COMP3031 Programming Assignment 1, Fall 2012
Author: Dekai Wu
Date: Due 2012.09.30 at 23:00 by CASS
Download: http://www.cs.ust.hk/~dekai/3031/assignments/a1.tar.gz
Assignment page: http://www.cs.ust.hk/~dekai/3031/assignments/a1/html/
Course page: http://www.cs.ust.hk/~dekai/3031/
Your assignment
You've been assigned to write an expression evaluator. The input expressions to your evaluator will be strings in a traditional computer science notation known as s-expressions, which is a prefix notation that is fully parenthesized to avoid ambiguity, for example:
(+ 2 3 4 5)
(+ 2 3.5)
(+ 2)
(+)
(+ (+ -2 5 -1) 3.5)
(ceiling 4.7)
(ceiling 4.0)
(ceiling -4.7)
(if 5 7 8.3)
(if 0 7 8.3)
(if (+ 2 3) (ceiling 6.1) (+ 4 2.3 2))
(if (+ 2 -2) (ceiling 6.1) (+ 4 2.3 2))
(+ 1 (if (+ 2 -2) (ceiling 6.1) (+ 4 2.3 2)))
Notice that you're dealing with three distinct types of atomic elements in these expressions: ints, doubles, and symbols. The ints and doubles are two different types of literals used as operands. In addition, the operator symbols are functions whose symbol names are +, if, and ceiling.
The + operator accepts any number of operands to be added. The operands can be any mix of ints or doubles. Like in C or C++, the return type should be double if any of the operands are double, and int otherwise. If no operands are given, then the result should be zero which is the identity value for addition.
The ceiling operator requires exactly one operand, which must be a double. It returns an int which is the smallest integer that is greater or equal to the operand.
The if operator requires either two or three operands. It first checks if the first operand is non-zero. If so, then it should return the result of evaluating the second operand. Otherwise, it should return the result of evaluating the third operand (if only two operands were given, then the return value is undefined, or in other words, you may return anything you like).
Also notice that operands do not have to be literals. They also can recursively be sub-expressions.
Given such an input expression, your evaluator should return the result of evaluating the expression, for example:
(+ 2 3 4 5) should return the int 14
(+ 2 3.5) should return the double 5.5
(+ 2) should return the int 2
(+) should return the int 0
(+ (+ -2 5 -1) 3.5) should return the double 5.5
(ceiling 4.7) should return the int 5
(ceiling 4.0) should return the int 4
(ceiling -4.7) should return the int -4
(if 5 7 8.3) should return the int 7
(if 0 7 8.3) should return the double 8.3
(if (+ 2 3) (ceiling 6.1) (+ 4 2.3 2)) should return the int 7
(if (+ 2 -2) (ceiling 6.1) (+ 4 2.3 2)) should return the double 8.3
(+ 1 (if (+ 2 -2) (ceiling 6.1) (+ 4 2.3 2))) should return the double 9.3
Your expression evaluator should proceed in two independent stages:
- Parse the input string to analyze and understand its structure. The parser should return a tree data structure in which it records (a) the nested structure of the parenthesized expressions and sub-expressions, and (b) the types of all the elements in the expression.
- Evaluate the expression stored in the tree data structure, by doing a depth-first traversal. The evaluator should return the value resulting from evaluating the entire expression.
If there is any error in the types or number of operands in the input expression, your expression evaluator should print the string ERROR on standard error (cerr << "ERROR"), and call exit(1) to terminate program execution. Otherwise, for this assignment, you may assume that you will only be tested with input expressions that can safely be parsed.
Borrowing someone else's expression parser
Thankfully, you don't have to write a parser. You've already found a parser written by someone else, capable of reading and understanding strings in s-expression format. Download the package at the top of this page, then:
$ tar xzf a1.tar.gz // unpack the archive
$ cd a1
$ make
g++ -c main.cpp
g++ -c parse.cpp
g++ -c eval.cpp
g++ -c Cell.cpp
g++ -DOP_ASSIGN -o main main.o parse.o eval.o Cell.o -lm
$ main testinput.txt
You will see the parser's test program run. You can also run the program in interactive mode by typing main without any command-line arguments. In interactive mode, the program will prompt you to type in an expression, and then it'll print the expression back to you, and repeat until you type control-D to generate an EOF (end-of-file).
You wish to re-use this code for parsing s-expressions. The only problem is that this parser, as originally written, does not actually build a tree data structure. So you will need to modify the code to suit the purposes of this assignment.
But you are lucky that the author of the parser encapsulated his code quite neatly. You will not even have to touch his parser code (which is in parse.hpp and parse.cpp). As the parser analyzes the input string, it needs to call various operations to record the nested tree structure that it is finding in the s-expression. The author wisely encapsulated all these operations and global constants in a separate header file cons.hpp that keeps all the concrete tree implementation details hidden from the parser:
-
Cell* make_int(const int i)returns a newly constructed int cell, i.e., a leaf node initialized to hold the int valuei -
Cell* make_double(const double d)returns a newly constructed double cell, i.e., a leaf node initialized to hold the double valued -
Cell* make_symbol(const char* const s)returns a newly constructed symbol cell, i.e., a leaf node initialized to hold the symbol names -
Cell* cons(Cell* const my_car, Cell* const my_cdr)returns a newly constructed cons cell, i.e., an internal node initialized to hold the two pointersmy_carandmy_cdr
-
bool intp(Cell* const c)returns true iff the cell pointed to bycis an int cell -
bool doublep(Cell* const c)returns true iff the cell pointed to bycis a double cell -
bool symbolp(Cell* const c)returns true iff the cell pointed to bycis a symbol cell -
bool nullp(Cell* const c)returns true iffcis is the null pointer (which is equivalent to the empty list) -
bool listp(Cell* const c)returns true iff the cell pointed to bycis a cons cell, or ifcis the null pointer (i.e., if c points to an empty list)
-
extern Cell* const nilholds the value of a null pointer, which we consider equivalent to an empty list
-
int get_int(Cell* const c)returns the value in the int cell pointed to byc(error ifcis not an int cell) -
double get_double(Cell* const c)returns the value in the double cell pointed to byc(error ifcis not a double cell) -
string get_symbol(Cell* const c)returns the value in the string cell pointed to byc(error ifcis not a string cell) -
Cell* car(Cell* const c)returns the car pointer of the cons cell pointed to byc(error ifcis not a cons cell) -
Cell* cdr(Cell* const c)returns the cdr pointer of the cons cell pointed to byc(error ifcis not a cons cell)
-
ostream& operator<<(ostream& os, Cell* const c)prints the cons cell pointed to bycto the output streamos, using s-expression notation
Notice that even though these are just ordinary functions (not member functions of a class), nevertheless this set of functions constitutes an interface for an abstract data type; we'll discuss more background on this particular ADT below. The way that cons.hpp specifies the ADT interface is nice because it makes very few assumptions about how the concrete implementation might be done. (Good object-oriented programming style does not necessarily require using classes! For example, see Scott Myer's article How Non-Member Functions Improve Encapsulation.)
The file cons.hpp that came with the parser just connects all the functions to a dummy example implementation of the ADT that makes use of a super-simple, incomplete Cell class probably written by someone else (found in Cell.hpp and Cell.cpp). As mentioned earlier, this dummy example implementation isn't actually capable of building a tree data structure with pointers and nodes. Instead, it just records the sub-trees using a string encoding, rather than a tree data structure. Most of the functions needed by cons.hpp aren't even working yet in the dummy Cell class, since the basic parser can be run without the accessor functions intp, doublep, symbolp, nullp, listp, get_int, get_double, get_symbol, car and cdr. You can build trees without using these accessor functions, although it's not terribly useful without the accessor functions since nobody can access the tree you've built. (And in fact, the string encoding that's used is actually just s-expression notation again! Of course this circular set-up is not terribly useful, either; it's just a partial example to show you how to work with the cons.hpp ADT interface by connecting it to a concrete implementation in Cell.hpp.)
So the parser author (me) and the tree data structure author (you) both have interfaces encapsulating our code, helping us to divide and conquer the work in both directions:
-
parse.hppis the interface that tells you what the parser can do, while hiding the dirty implementation details of how the parser works (in myparse.cppwhich your tree data structure doesn't get to see). -
cons.hppis the interface that tells me what the tree data structure can do, while hiding the dirty implementation details of how the tree data structure works (in yourCons.hppandCons.cppwhich my parser doesn't get to see).
Adapting the parser to this assignment
You realize that the cleanest and easiest way to proceed is to leave cons.hpp exactly the way it is. That way, you only need to replace the Cell class with your own implementation. (This is good software engineering at work, helping you through proper encapsulation!)
You will also stick to re-using the existing interface of the Cell class when implementing your own version of Cell; you won't delete or rename any functions or member functions, to avoid breaking the parser. (However, you might wish to add some new functions and member functions, to support manipulating and accessing the tree data structure you build.)
Looking at the public interface specified by the Cell class in Cell.hpp, you see there are a few constructors that the parser's cons.hpp will expect your own implementation to provide:
-
Cell(const int i)constructs an int cell, i.e., a leaf node that holds the int valuei -
Cell(const double d)constructs a double cell, i.e., a leaf node that holds a double valued -
Cell(const char* const s)constructs a symbol cell, i.e., a leaf node that holds the symbol names -
Cell(Cell* const my_car, Cell* const my_cdr)constructs a cons cell, i.e., an internal node that holds two pointersmy_carandmy_cdr
Other than these constructors, you'll need to implement these public member functions:
-
bool is_int() constreturns true iffthisis an int cell -
bool is_double() constreturns true iffthisis a double cell -
bool is_symbol() constreturns true iffthisis a symbol cell -
bool is_cons() constreturns true iffthisis a cons cell
-
int get_int() constreturns the value in this int cell (error ifthisis not an int cell) -
double get_double() constreturns the value in this double cell (error ifthisis not a double cell) -
string get_symbol() constreturns the symbol name in this symbol cell (error ifthisis not a symbol cell) -
Cell* get_car() constreturns the car pointer of this cons cell (error ifthisis not a cons cell) -
Cell* get_cdr() constreturns the cdr pointer of this cons cell (error ifthisis not a cons cell)
-
void print(ostream& os) constprints the subtree rooted at this cell, in s-expression notation
In Cell.cpp you'll also need to define this global constant, that was declared as an extern in cons.hpp (and in Cell.hpp too):
-
Cell* const nilis the value for a null pointer, which we consider equivalent to an empty list.
Hint: depending on your approach, you could choose either to implement nil as the C++ NULL value (the pointer to address zero), or as some unique dummy Cell* value (known as a sentinel, as you should learn in COMP171). If you don't know what this means yet, then don't worry and just implement nil as the C++ NULL value, exactly as in the dummy version of Cell.cpp that we give you. The following sections discuss how nil is used.
Some background on the cons list ADT
The abstract data type (ADT) that the parser author chose to use is a traditional cons list ADT dating back to around 1958. This ADT only requires a nil or NULL constant representing an empty list (which can be written () using s-expression notation), plus only three essential core operations cons, car and cdr:
-
cons constructs a new list with a given car value and cdr list. For example:
-
cons(1, nil)returns(1) -
cons(1, cons(2, nil))returns(1 2) -
cons(1, cons(2, cons(3, nil)))returns(1 2 3) -
cons(cons(1, cons(2, nil)), cons(3, nil))returns((1 2) 3)
-
-
car gives the value of the head node of the list. For example:
-
car(cons(1, nil))returns1 -
car(cons(cons(1, nil), nil))returns(1) -
car(cons(cons(1, cons(2, nil)), cons(3, nil)))returns(1 2)
-
-
cdr (pronounced "could-er" or "cudder") gives the list after the head node. For example:
-
cdr(cons(1, cons(2, cons(3, nil))))returns(2 3) -
cdr(cons(cons(1, cons(2, nil)), cons(3, nil)))returns(3)
-
Building up large trees this way can get a bit tedious, so in practice typically people also define equivalent shorthand functions. Mathematically speaking, such functions are not really necessary, and exist only for the sake of convenience. For example,
-
list builds a new list containing the operands. For example:
-
list(1)is shorthand forcons(1, nil)and returns(1) -
list(1, 2, 3)is shorthand forcons(1, cons(2, cons(3, nil)))and returns(1 2 3) -
list(list(1, 2), 3)is shorthand forcons(cons(1, cons(2, nil)), cons(3, nil))and returns((1 2) 3)
-
To keep your life simple, you are not required to implement list even though we'll use it in written examples later.
Implementing the cons list ADT
How do you implement the cons list ADT? In fact there exist many different implement approaches.
You've decided to use the most traditional approach, which is to use a singly linked list data structure (recall Lab 2). This is the most natural and intuitively obvious way to implement the cons list ADT. As explained in Wikipedia:
Specifically, each node in the linked list is a cons cell, also called a pair. As the name pair implies, a cons cell consists of two values: the first one is the car, and the second is the cdr. For list(1, 2, 3), there are three cons cells, or pairs. The first cons cell has the number 1 in the first slot, and a pointer to the second cons cell in the second. The second cons cell has the number 2 in the first slot, and a pointer to the third cons cell in the second slot. The third cons cell has the number 3 in the first slot and a NULL constant in the second slot. The NULL constant is usually represented by (). The cons function constructs these cons cells, which is why cons(1, list(2, 3)) gives the list (1 2 3).
Here's a picture of the linked list to hold ((1 2) 3), using what's known as box-and-pointer notation. Notice how it naturally matches the exact structure of cons(cons(1, cons(2, nil)), cons(3, nil)). There's one box for each cons, and two nil pointers.
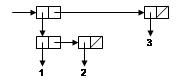
In this assignment, cells can hold four kinds of values: int, double, symbol, and cons. You need a way to store any of these types of values in your cells. How do you do this efficiently?
The obvious naive way is just to have four data members:
class Cell { ... int int_m; double double_m; char* symbol_m; ConsPair conspair_m; };
But this is a terribly inefficient waste of memory. Any instance of a Cell will only be using one of these data members. So a better way is to use a union:
class Cell { ... union { int int_m; double double_m; char* symbol_m; ConsPair conspair_m; }; };
Unions exist in both C and C++. A union is sort of like a struct, except that a struct provides memory space to simultaneously store all its members, whereas a union provides memory space to store only one of its members at a time. So this way, we won't waste memory space.
The only problem is: when you're using a union, how do you know which of the data members is the valid one? C++ won't tell you; it is your program's own responsibility to keep track of this. If you don't, you can easily create horrible bugs. For example:
Cell* c = new Cell;
c->double_m = 2.718;
cout << c->int_m; // whoops! will print out a garbage int
cout << c->symbol_m; // whoops! will either seg fault or do wildly unpredictable things
To keep track of which member in the union is currently valid, you should use what's known as a tagged union or discriminated union approach:
class Cell { ... enum TypeTag {type_int, type_double, type_symbol, type_conspair}; TypeTag tag_m; union { int int_m; double double_m; char* symbol_m; ConsPair conspair_m; }; };
Now you can write your code so that you make sure that the tag_m always holds an up-to-date value indicating which of the union members is valid at the current time.
Evaluating the expression tree
After you've gotten the parser to store the expression into your real tree data structure (your concrete implementation of the cons list ADT), now you need to write a function that evaluates it.
To do this, you merely need to perform a depth-first traversal starting from the root. As you complete each subtree, the evaluator should return the value resulting from evaluating the sub-expression stored in that subtree. By the time you finish the entire traversal, you will be back at the root---so the evaluator should return the value resulting from evaluating the entire expression.
The problem is: what is the type that should be returned by your evaluator function?
It would seem that this depends on the type of the operands---remember, from the introduction:
(+ 2 3 4 5) should return the int 14
(+ 2 3.5) should return the double 5.5
(+ (+ 3 -1) 3.5) should return the double 5.5
(if 5 7 8.3) should return the int 7
(if 0 7 8.3) should return the double 8.3
(if (+ 2 3) (+ 4 3) (+ 6 2.3)) should return the int 7
(if (+ 2 -2) (+ 4 3) (+ 6 2.3)) should return the double 8.3
(+ 1 (if (+ 2 -2) (+ 4 3) (+ 6 2.3))) should return the double 9.3
(ceiling 4.7) should return the int 5
(ceiling -4.7) should return the int -4
But C++ won't let us write a function that returns different types depending on the result!
To solve this problem, we'll re-use your Cell implementation. Remember, Cell already gives us a way to store different types of values in the same class type, by using a tagged union. So your function evaluator should return a Cell* that points to a Cell holding the value resulting from evaluating the expression:
-
Cell* eval(Cell* const c)returns the value resulting from evaluating the expression tree whose root is pointed to byc(error ifcis not a well-formed expression)
You'll find this declaration in the header file eval.hpp, which you should not alter. Place your implementation for the evaluator in your own eval.cpp file, replacing the dummy eval.cpp that came with the parser.
When you're implementing the eval function, think carefully about all the different cases (what type are the operands?) The + and if functions can be applied to any combination of the numeric int and double types, but what is the return type? The ceiling function can be applied to double types, but not int types. No function can be applied to the symbol type (yet).
Putting it all together
Notice that the dummy example implementation of eval.cpp that you have been given doesn't do anything useful. It just returns the same Cell* that was passed to it. That's why running the main program prints out the same s-expression that you give it as input. After you've correctly replaced eval.cpp with your real evaluator implementation, running the same main program will instead print out the result of evaluation---which is exactly what we want!
So you don't need to touch main.cpp at all. Good encapsulation at work, again!
Important reminders
You must follow the design approach outlined in this document. Do not just implement the required functionality using a different design. Your proper software engineering skills are being graded.
Do not use virtual functions or templates in this assignment. This assignment is about static OO support in C++. (You'll get a chance to use dynamic OO polymorphism and templates in the following assignments...)
Do not edit the files parse.hpp, parse.cpp, cons.hpp, eval.hpp, or main.cpp. The programming assignments are mini-exercises in how multiple programmers are supposed to interact and communicate in the real world; these files are owned and maintained by the other author(s).
You will need to add things to Cell.hpp, but do not delete anything from it. Replace the files Cell.cpp and eval.cpp with your own implementations. Depending on your approach, you may or may not also wish to add more files.
Depending on your approach, you may or may not need to change the Makefile (as in Lab 1). Whether you changed it or not, always make sure you include whatever Makefile is needed to build your program, when you submit the assignment. Otherwise, the graders cannot build your program.
Documentation is also a critically important part of your software engineering. Your use of doxygen comments, as in Lab 3, will be graded.
You must write the final version of the program on your own. Sophisticated plagiarism detection systems are in operation, and they are pretty good at catching copying! If you worked in study groups, you must also acknowledge your collaborators in the write-up for each problem, whether or not they are classmates. Other cases will be dealt with as plagiarism. Re-read the policy on the course home page, and note the University's tougher policy this year regarding cheating.
Your programming style (how clearly and how well you speak C++) is what will be graded. Correct functioning of your program is necessary but not sufficient!
Grading scheme
Below is the grading sheet that will be used by the graders, so you can see what software engineering skills they're checking you for.
Your grade consists of two parts: (1) program correctness, worth 60%. and (2) style & design, worth 40%. Points are deducted for the error types as shown (but the minimum you can get for each part is 0%, so you cannot get negative point scores on either program correctness or style & design).
To assist you with your own testing and debugging, examples of the simple, general, and invalid input test cases (similar to the real ones that will be used by the graders) are found in the files testinput_simple.txt, testinput_general.txt, and testinput_invalid.txt, respectively. The correct results for the valid cases are found in the files testreference_simple.txt and testreference_general.txt.
| Name: | |
| Email: | |
| Submission Time: | |
| Late Penalty: | |
| Total Pts: | / 100 Pts |
| PROGRAM CORRECTNESS (Maximum: 60 Pts; Minimum: 0 Pts) | ||
| Description | Pts | Notes |
| Base Pts. (+60 Pts) | ||
| Program fails to compile. (-60 Pts) | ||
| Cell class fails (link against reference solution and run tests) (-60 Pts) | ||
| eval() does not pass simple test cases. (-15 Pts) | ||
| eval() does not pass general test cases. (-15 Pts) | ||
| eval() does not handle semantically invalid cases. (-15 Pts) | ||
| Does print() print s-expressions properly? (-20 Pts) | ||
| Program prints irrelevant information. (-10 Pts) | ||
| Encapsulation (Min -40 Pts) | ||
| BONUS: Proper destruction (+10 Pts) | ||
| BONUS: Detailed error messages (+5 Pts) | ||
BONUS: Expressions like ((if 1 + ceiling) 3.1) (+5 Pts) | ||
| STYLE & DESIGN (Maximum: 40 Pts; Minimum: -100 Pts) | ||
| Description | Pts | Notes |
| Base Pts. (+40 Pts) | ||
| No Doxygen output. (-10 Pts) | ||
| Inadequate function level documentation. (-10 Pts) | ||
| Inadequate algorithm level (i.e. within function) documentation. (-15 Pts) | ||
| Inadequate variable level documentation (i.e. meaning of the variable). (-10 Pts) | ||
| Poor readability of function and variable names. (-10 Pts) | ||
| Improper use of indentation and space. (-10 Pts) | ||
| Inconsistent naming of functions and variables. (-10 Pts) | ||
| Incorrect ‘const’ usage. (-10 Pts) | ||
| Improper private data encapsulation. (-10 Pts) | ||
